首先我们要新建一个类,一个类里面要有三部分
第一部分:初始化 第一,打开文件 1 2 3 4 5 6 def __init__ (____________ ): with open (file_train,"r" ) as f: csv_data = list (csv.reader(file_train)) column = csv_data[0 ] x = csv_data[1 :, 1 :-1 ] y = csv_data[1 :, -1 ]
一、with open(file_train,”r”) as f中的with和as f是干嘛用的? with:自动关闭文件。相当于open()打开而自动使用close()关闭。若只open不close,会导致文件一直被程序占用,其他程序无法打开导致内存泄漏。
as f:相当于给文件命名
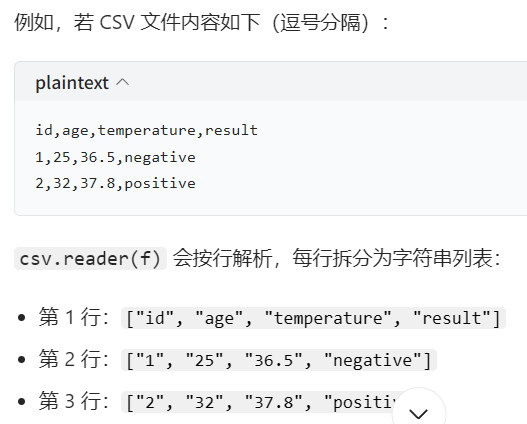
二、为什么需要list()? 因为csv.reader()的作用是按照行分隔符(“/n”)和列分隔符(“,”)做切割,如
但这个功能是一个迭代器,只能单向遍历一次,不能索引,故需要转换成list以便于直接访问
第二,特征筛选(可选) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 def get_feature_importance (feature_data, label_data, k =4 ,column = None ): model = SelectKBest(chi2, k=k) feature_data = np.array(feature_data, dtype=np.float64) X_new = model.fit_transform(feature_data, label_data) print ('x_new' , X_new) scores = model.scores_ indices = np.argsort(scores)[::-1 ] if column: k_best_features = [column[i+1 ] for i in indices[0 :k].tolist()] print ('k best features are: ' ,k_best_features) return X_new, indices[0 :k] if all_feature: col_indices = np.array([i for i in range (0 ,93 )]) col_indices = col_indices.tolist() else : _,col_indices = get_feature_importance(x,y,feature_dim,column) col_indices = col_indices.tolist() csv_data = np.array(csv_data[1 :])[:, 1 :].astype(float )
feature_data, label_data分别是什么参数? 是x和y,即用来训练的数据部分和用来训练的已知的训练结果标签
第三,拆分数据集(只处理了y) 训练集逢五取四,验证集逢五取一,测试集全取。
y是训练、验证的标签,由于是这个类里面其他函数也要用的部分,故用self.y变成全局的。由于要后续使用,故转换成tensor
1 2 3 4 5 6 7 8 if mode == "train" : indices = [i for i in range (len (csv_data)) if i % 5 !=0 ] self .y = torch.tensor(csv_data[indices,-1 ]) elif mode == "val" : indices = [i for i in range (len (csv_data)) if i % 5 ==0 ] self .y = torch.tensor(csv_data[indices,-1 ]) else : indices = [i for i in range (len (csv_data))]
第四,特征提取(处理x),归一化,校验 1 2 3 4 5 6 7 data = torch.tensor(csv_data[indices,:]) data = torch.tensor(csv_data[:,col_indices]) self .data = dataself .mode = modeself .data = (self .data - self .data.mean(dim=0 ,keepdim=True )) / self .data.std(dim=0 ,keepdim=True ) assert feature_dim == self .data.shape[1 ]print ('Finished reading the {} set of COVID19 Dataset ({} samples found, each dim = {})' .format (mode, len (self .data), feature_dim))
归一化? 标准化(Z-Score)公式
这段代码实现的归一化遵循严格的数学公式:
$X_{norm} = \frac{X - \mu}{\sigma}$
其中:
X :原始特征数据(这里是 self.data 张量中的某个特征的所有样本值)μ (mu):该特征的均值 (所有样本在该特征上的平均值,对应代码中 self.data.mean(dim=0, keepdim=True))σ (sigma):该特征的标准差 (所有样本在该特征上的离散程度,对应代码中 self.data.std(dim=0, keepdim=True))X norm:标准化后的特征数据,最终满足「均值为 0,标准差为 1」的分布特性
dim=0,为啥是对列归一化? dim为0按列,为1按行
归一化的本质是对「特征」做预处理,每一列对应一个独立特征,每一行对应一个样本的特征集合,按列归一化是符合深度学习 / 机器学习逻辑的必然选择,按行归一化无实际业务和模型意义 。
keepdim=True 的作用?keepdim默认为false,即计算过程中压缩计算维度为1维,会使维度不匹配而报错。令其为true可使张量维度保持不变。
assert在这里的作用? 保险措施,强制校验特征维度 ,提前暴露特征筛选错误,避免后续模型训练时出现维度不匹配异常。
self.data.shape[1]:获取归一化后特征张量的列数(即实际筛选得到的特征维度),self.data.shape[0] 是样本数;feature_dim:用户指定的目标特征维度(k,即要保留的重要特征数);
assert 断言的作用:
第五,getitem和len 支持通过下标(索引)item 读取数据集对应位置的数据
1 2 3 4 5 6 7 def __getitem__ (self, item ): if self .mode == "test" : return self .data[item].float () else : return self .data[item].float (),self .y[item].float () def __len__ (self ): return len (self .data)
另外,类的书写和函数不一样,类会调用括号里面的基类,如Dataset,nn.Module 1 2 3 4 5 6 7 class myNet (nn.Module): def __init__ (self,inDim ): super (myNet,self ).__init__() self .fc1 = nn.Linear(inDim, 64 ) self .relu = nn.ReLU() self .fc2 = nn.Linear(64 ,1 )
1 2 3 4 5 6 7 8 class covidDataset (Dataset ): def __init__ (self, path, mode="train" , feature_dim=5 , all_feature=False ): with open (path,'r' ) as f: csv_data = list (csv.reader(f)) column = csv_data[0 ] x = np.array(csv_data)[1 :,1 :-1 ] y = np.array(csv_data)[1 :,-1 ]
为啥Module要super,Dataset却不用? 因为Dataset并没有用到什么高级的方法,都是我自己定义的。
而myNet需要用到Module基类里的高级方法,如果不super,模型就识别不出fc1、relu、fc2有何意味。
super的用法:
第六,前向传播 1 2 3 4 5 6 7 8 def forward (self,x ): x = self .fc1(x) x = self .relu(x) x = self .fc2(x) if len (x.size()) > 1 : return x.squeeze(1 ) else : return x
squeeze起什么作用?不是已经被压缩到一维了吗? 虽然self.fc2 = nn.Linear(64,1)确实把维度降到了一,但实际上还是形状为(样本数量,1)的二维张量。这让结果看起来是一个n*1的矩阵,而squeeze的作用就是把结果转换为大小为n的一维数组
第七,模型训练验证中的训练部分 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 def train_val (model, trainloader, valloader, optimizer, loss ,epoch,device,save_ ) model =model.to(device) plt_train_loss = [] plt_val_loss = [] val_rel = [] min_val_loss = 1000000 for i in range (epoch): strat_time = time.time() model.train() train_loss = 0.0 val_loss = 0.0 for data in trainloader: optimizer.zero_grad() x, target = data[0 ].to(device),data[1 ].to(device) pred = model(x) bat_loss = loss(pred,target,model) optimizer.step() train_loss += bat_loss.detach().cpu().item() plt_train_loss. append(train_loss/trainloader.dataset.__len__())
这些参数分别啥意思? model模型, trainloader训练集数据, valloader验证集数据,
optimizer动态调整梯度的调节方向和调节速率,通过学习率控制,
loss 损失,epoch训练轮次,device设备,save_保存到哪里
model =model.to(device)什么作用? 把模型搬到同一个设备上,保证在同一块CPU或者GPU上运行
optimizer.zero_grad()? 清空每一批数据的梯度,防止被传到下一批中影响结果,导致参数更新错误
梯度可以类比学生错在哪里的错题分析。如果新的一轮不清除上一轮的错题分析,会影响新一轮批次的梯度。
pred = model(x)? model(x) 会自动触发 model.forward(x) 方法,这是 PyTorch 帮我们封装好的便捷操作
把输入数据 x 传入模型,让模型按照你定义的 forward 方法执行计算,最终返回预测结果 pred(存到 pred 变量里)。
bat_loss = loss(pred,target,model) 即batch_loss,loss()是函数传入的损失函数,且得到的结果是一个一维张量,想要使用他还要转成数字
trainloader.dataset.len () 记录每一轮训练的平均损失值,为后续绘制损失曲线做准备。训练集的 “总题数”(总样本数)
第八,模型训练验证中的验证部分 1 2 3 4 5 6 7 8 9 10 model.eval () with torch.no_grad(): for data in valloader: val_x, val_target = data[0 ].to(device), data[1 ].to(device) val_pred = model(val_x) val_bat_loss = loss(val_pred,val_target,model) val_loss += val_bat_loss.detach().cpu().item() if val_loss < min_val_loss: torch.save(model, save_) plt_val_loss.append(val_loss/valloader.dataset.__len__())
注意点 第一、model切换训练模式是model.train(),但切换验证模式是eval()而不是val()
第二、若得到了更小的损失,torch.save(model, save_)保存的是模型
第九,输出模型结果 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def evaluate (model_path, testset,rel_path, device ): model = torch.load(model_path).to(device) testloader = DataLoader(testset,batch_size=1 ,shuffle=False ) val_rel = [] model.eval () for data in testloader: x = data.to(device) pred = model(x) val_rel.append(pred.item()) print (val_rel) with open (rel_path,"w" ) as f: csv_data = csv.writer(f) csv_data.writerow(['id' ,'tested_positive' ]) for i in range (len (testset)): csv_data.writerow([str (i),str (val_rel[i])])
shuffle有什么作用? 控制是否对数据集的样本顺序进行打乱,可以改变样本被模型读取的顺序。
在测试时需要打乱取True,若样本是按照类别排序或者有时间顺序,如果不打乱,模型会学习到虚假的特征而忽略了真正的特征,导致模型过拟合。比如你的训练集是按类别排的(先全是猫,再全是狗),不洗牌的话,模型会连续学很久猫,再连续学很久狗,容易学歪(比如误以为 “前面的都是猫,后面的都是狗”,而不是学猫和狗的本质特征)。
在验证和测试时不需要打乱取False,首先保证 id 和预测结果对得上:你要把样本索引i和预测结果一一写到 CSV 里(比如第 0 个样本对应第 0 个预测值),要是洗牌了,样本顺序乱了,你记录的预测结果就和原始样本对不上了,相当于 “张冠李戴”,后续根本没法追溯哪个样本对应哪个结果。其次,测试阶段洗牌没用,纯添乱:洗牌是为了帮模型更好训练,测试阶段模型已经定型了,不用再学东西,洗牌除了搞乱顺序,一点好处都没有。
第十,动手做数据准备 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 all_col = False device = 'cuda' if torch.cuda.is_available() else 'cpu' print (device)train_path = 'covid.train.csv' test_path = 'covid.test.csv' file = pd.read_csv(train_path) file.head() if all_col == True : feature_dim = 93 else : feature_dim = 6 trainset = covidDataset(train_path,'train' ,feature_dim=feature_dim, all_feature=all_col) valset = covidDataset(train_path,'val' ,feature_dim=feature_dim, all_feature=all_col) testset = covidDataset(test_path,'test' ,feature_dim=feature_dim, all_feature=all_col)
简单说,这段代码是机器学习项目的 “数据准备第一步” :先设置一些基础配置(是否用全量特征、选择 CPU/GPU),再读取 CSV 格式的原始数据,最后通过自定义数据集类把训练集、验证集、测试集都加载好,为后续模型训练和预测做准备。
定义损失函数 1 2 3 4 5 6 7 8 def mseLoss (pred,target,model ): loss = nn.MSELoss(reduction='mean' ) regularization_loss = 0 for i in model.parameters(): regularization_loss += torch.sum (i ** 2 ) return loss(pred,target) + regularization_loss * 0.00075 loss loss =mseLoss
loss = nn.MSELoss(reduction=’mean’) MSELoss是Mean Squared Error Loss的缩写,即均方误差损失,计算“模型预测值”和“真实标签值”之间的平均均方误差。mean是指误差计算的最终拟合方式,计算每个样本的均方误差,再计算它们的平均值
regularization_loss = 0 和 regularization_loss += torch.sum(i ** 2) regularization_loss = 0这个是正则项,初始为零,后续累加模型所有参数的惩罚值,通过给模型加惩罚项,可以避免模型过度拟合训练数据。
regularization_loss += torch.sum(i ** 2)是L2正则化。防止模型通过把参数拉大的方式只取得在训练集上的优秀表现导致在测试集上表现很差。加了 L2 正则化后,参数太大会被惩罚,模型只能学习数据的通用特征,而不是训练数据的噪声,从而提升泛化能力。
第十一,动手 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 config = { 'epochs' :50 , 'batch_size' :256 , 'optimizer' :'SGD' , 'optim_hparas' :{ 'lr' :0.0001 , 'momentum' :0.9 }, 'early_stop' :200 , 'save_path' :'model_save/model_path' } model = myNet(feature_dim).to(device) optimizer = optim.SGD(model.parameters(),lr=0.001 ,momentum=0.9 ) trainloader = DataLoader(train_set,config['batch_size' ],shuffle=True ) valloader = DataLoader(val_set,config['batch_size' ],shuffle=False ) train_val(model,trainloader,valloader,optimizer,loss,config['epochs' ],device,config['save_path' ]) evaluate(config['save_path' ],test_set,'pred.csv' ,device)
参数含义? SGD:随机梯度下降
optim_hparas:SGD的参数。lr是学习率,即模型更新的步长,太小导致收敛变慢,太大导致不收敛。momentum是动量,靠 “惯性冲力” 强行冲出局部最优的束缚,避免在局部最优解附近来回震荡。类比模拟退火靠 “一定概率接受差解” 的随机 性,跳出局部最优的陷阱。
early_stop:早停阈值,如果模型连续n轮验证集性能都没提升,就提前停止训练,避免无效训练浪费时间
optimizer = optim.SGD(model.parameters(),lr=0.001,momentum=0.9) “给模型分配一个‘助手’,这个助手会用 SGD 策略,按照指定的步长和惯性,帮模型调整参数,让模型的预测误差越来越小”

 微信
微信 支付宝
支付宝