
第七节自注意力机制
常见的输入
每个词对应一个编码,中文中对应差不多两万多个编码

这就组成了RNN
RNN需要考虑前后关系,故需要一个从头穿到尾的传家宝–记忆单元
但其弊端是,如果想要的信息之间距离过远,,RNN就会在传家宝里放一些没有帮助的东西。故引出了LSTM
LSTM
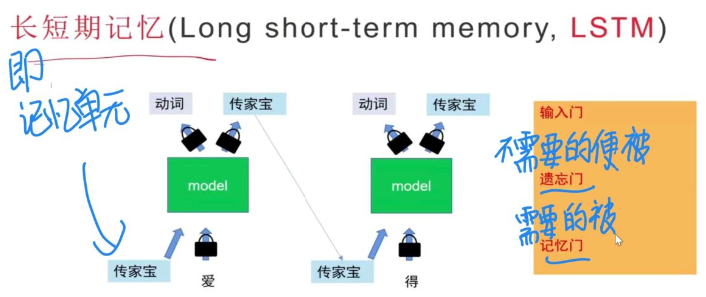
但缺点是太慢了,还是需要一个一个读入。故引出了自注意力
自注意力
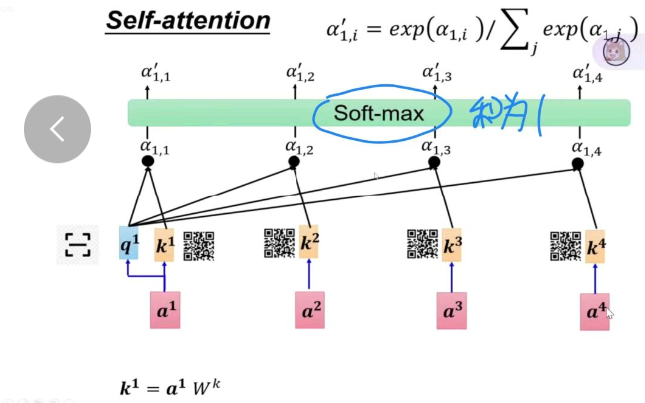
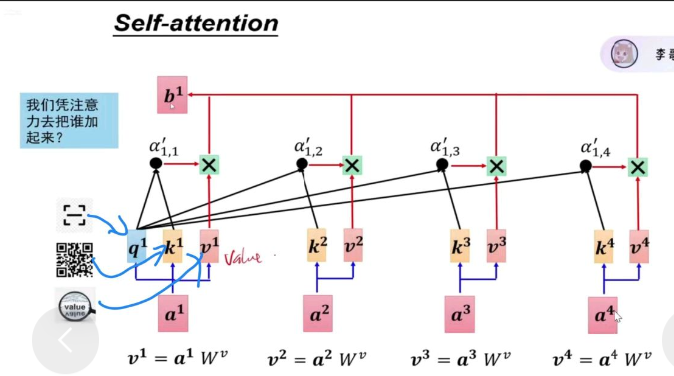
这样就解决了前两个模型需要查看每一个字导致时间过长的问题。自注意力是完全并行的!
而且自注意力在qkv处理过程中维度不变
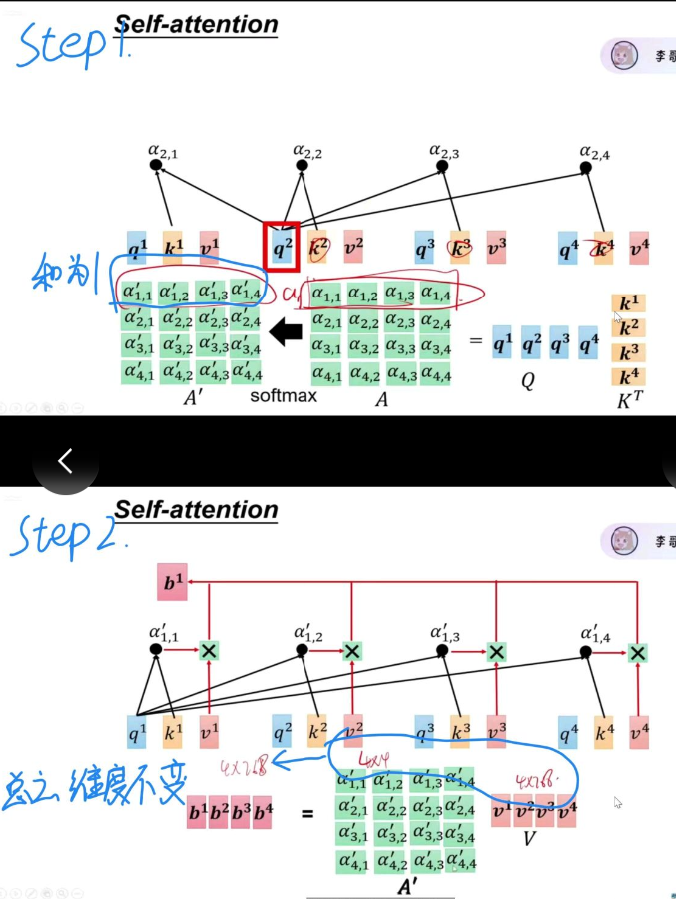
自注意力机制在干嘛?
自注意机制就是让句子里的每个词,都去 “看” 句子里的其他词,然后把有用的信息 “拿回来”,帮助自己变得更聪明。
QKV是干嘛的?
“他告诉小明,他明天要去北京。”
Q(Query):我要找谁?我想知道什么?我这个词在寻找和我相关的词时,用什么特征去匹配?是一个 “搜索条件”、一个 “问题”、一个 “需求描述”
比如 “他” 的 Q 可能是:“我是一个代词,我需要找到一个人来指代。”
K(Key):我是谁?我能提供什么信息?我这个词能提供什么信息?别人可以用什么方式找到我?是一个 “标签”、一个 “索引”、一个 “联系方式”
比如 “小明” 的 K 可能是:“我是一个人名,我可以被代词指代。”
V(Value):我真正的内容是什么?我这个词真正的内容是什么?你找到我后,你能拿到什么信息?
比如 “小明” 的 V 就是:“一个具体的人,名字叫小明。”
用一个生活例子把整个流程串起来
想象你在公司里找人合作一个项目。
你(当前词)有一个 Q:
“我需要一个懂 AI 的人。”
公司里每个人都有一个 K:
- 小明:K = “我懂 AI”
- 小红:K = “我懂设计”
- 小刚:K = “我懂 AI”
你用你的 Q 去对比所有人的 K:
- 小明匹配度高
- 小刚匹配度高
- 小红匹配度低
然后你把他们的 V 拿过来:
- 小明的 V = “AI 工程师,会深度学习”
- 小刚的 V = “AI 研究员,会大模型”
最后你得到一个综合后的自己:
“我现在知道我应该找小明和小刚合作。”
这就是自注意机制。
为什么一定要分成 Q、K、V?
因为要把 “搜索条件” 和 “被搜索的标签” 和 “实际内容” 分开,这样:
- Q 可以专注于 “我要找什么”
- K 可以专注于 “我能被怎么找到”
- V 可以专注于 “我能提供什么”
这种分离让模型表达能力更强,也更灵活。
如果只用一个向量,就像让一个人同时当:
- 求职者
- 面试官
- 简历内容
会非常混乱。
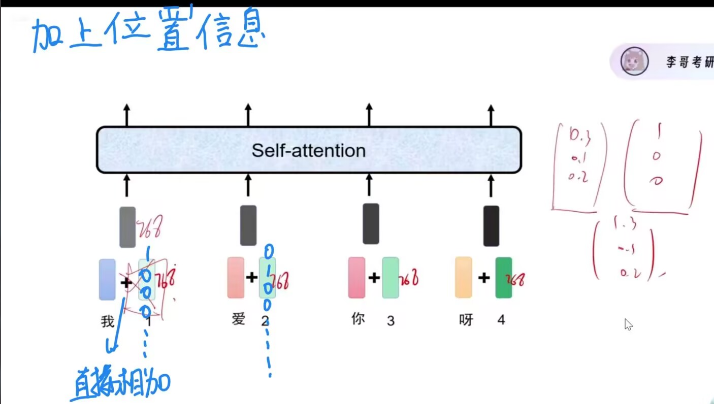
最后再加上位置信息
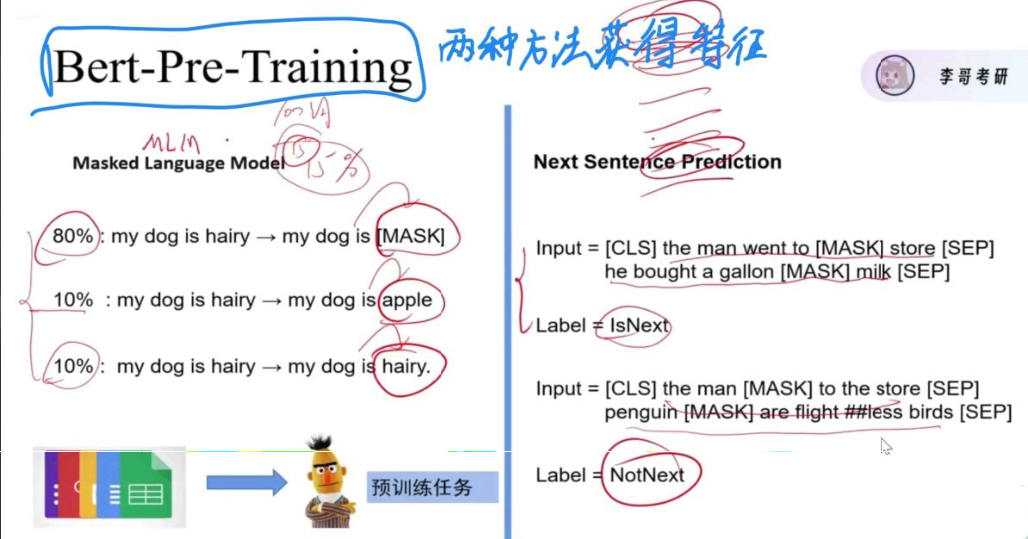
有两种方法获得特征
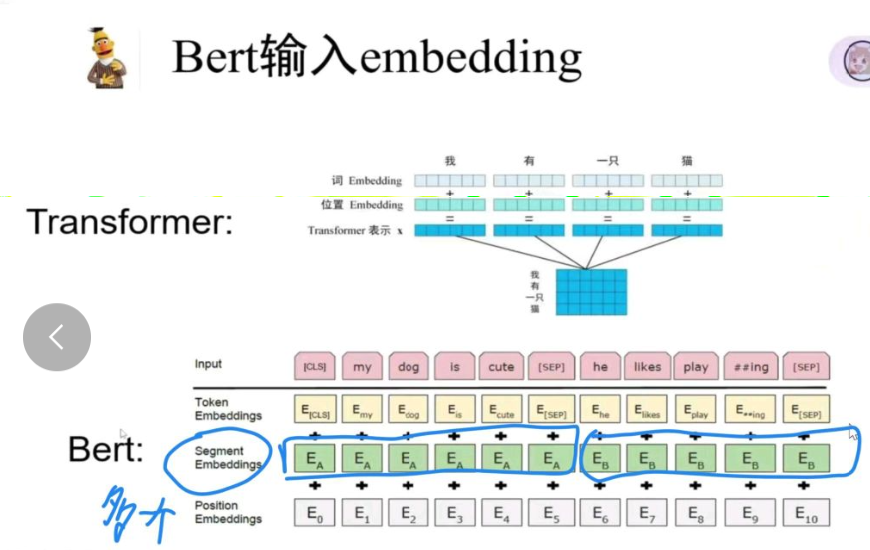
BERT的输入比transformer多一层
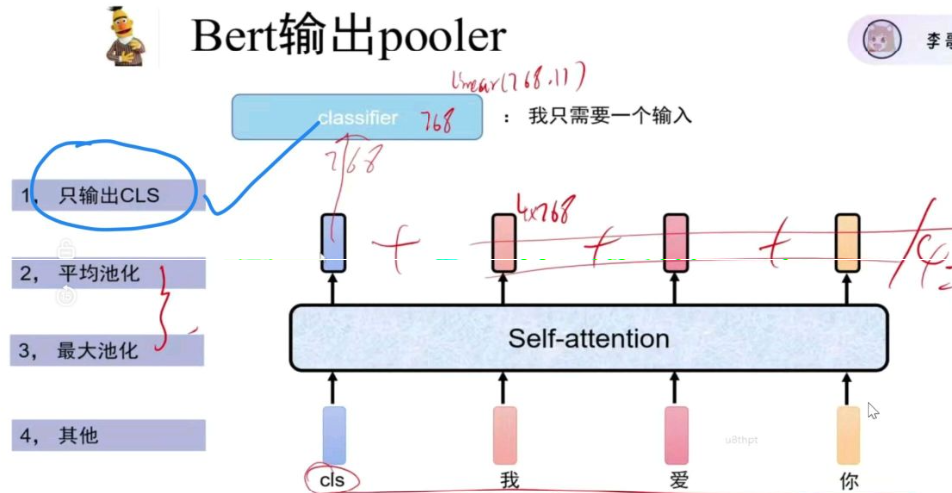
Bert的输出pooler有很多种方式,但一般都是第一种
总结

 微信
微信 支付宝
支付宝