
第七节自注意力机制
常见的输入
每个词对应一个编码,中文中对应差不多两万多个编码

这就组成了RNN
RNN需要考虑前后关系,故需要一个从头穿到尾的传家宝–记忆单元
但其弊端是,如果想要的信息之间距离过远,,RNN就会在传家宝里放一些没有帮助的东西。故引出了LSTM
LSTM
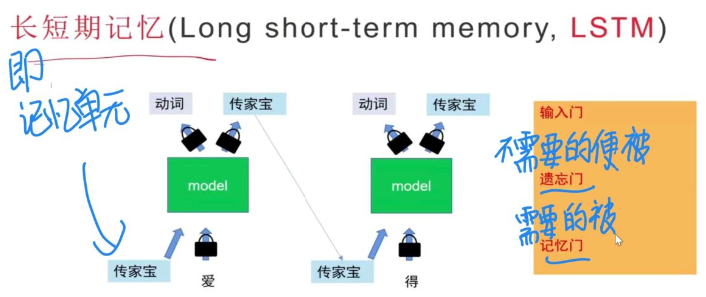
但缺点是太慢了,还是需要一个一个读入。故引出了自注意力
自注意力
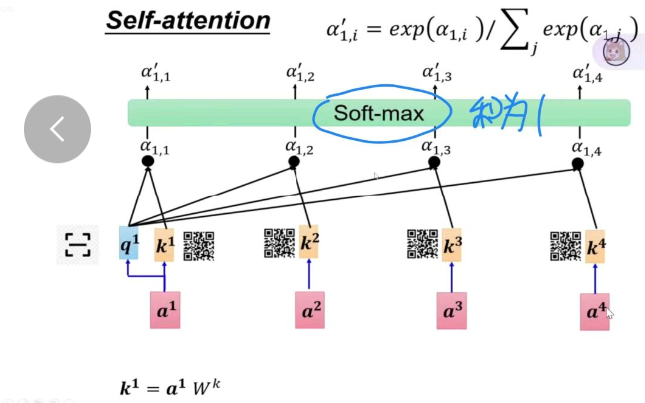
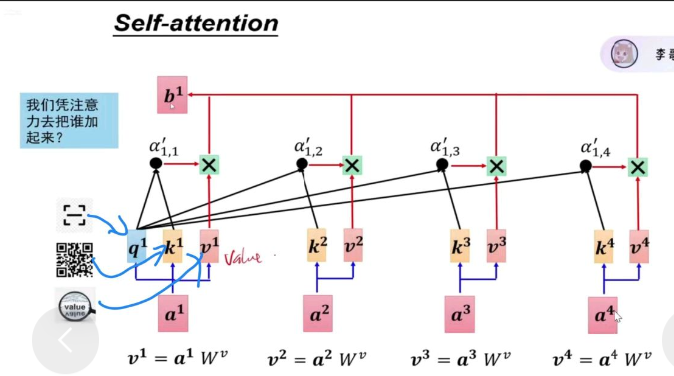
这样就解决了前两个模型需要查看每一个字导致时间过长的问题。自注意力是完全并行的!
而且自注意力在qkv处理过程中维度不变
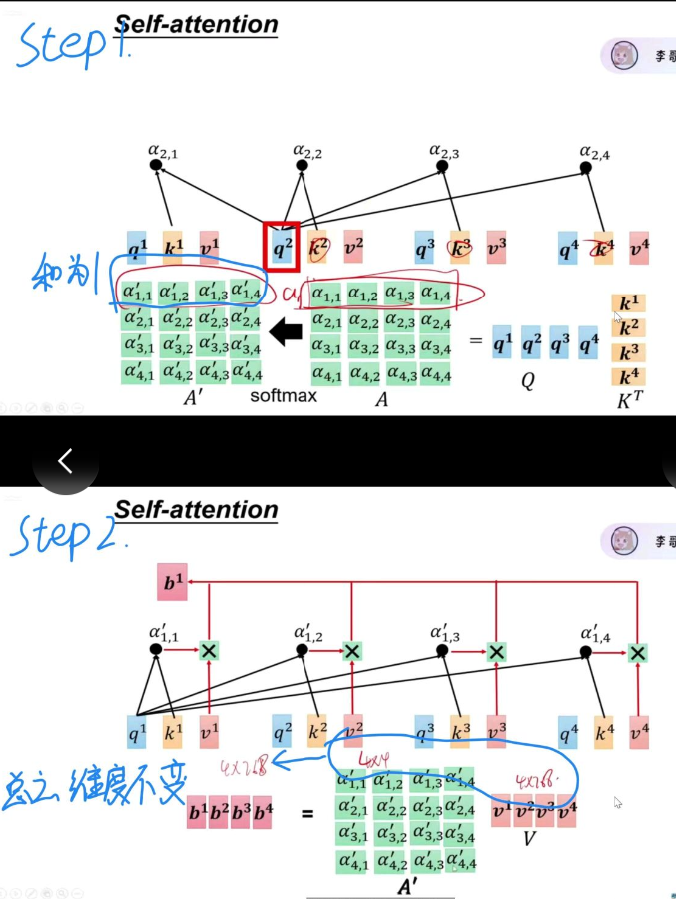
自注意力机制在干嘛?
自注意机制就是让句子里的每个词,都去 “看” 句子里的其他词,然后把有用的信息 “拿回来”,帮助自己变得更聪明。
QKV是干嘛的?
“他告诉小明,他明天要去北京。”
Q(Query):我要找谁?我想知道什么?我这个词在寻找和我相关的词时,用什么特征去匹配?是一个 “搜索条件”、一个 “问题”、一个 “需求描述”
比如 “他” 的 Q 可能是:“我是一个代词,我需要找到一个人来指代。”
K(Key):我是谁?我能提供什么信息?我这个词能提供什么信息?别人可以用什么方式找到我?是一个 “标签”、一个 “索引”、一个 “联系方式”
比如 “小明” 的 K 可能是:“我是一个人名,我可以被代词指代。”
V(Value):我真正的内容是什么?我这个词真正的内容是什么?你找到我后,你能拿到什么信息?
比如 “小明” 的 V 就是:“一个具体的人,名字叫小明。”
用一个生活例子把整个流程串起来
想象你在公司里找人合作一个项目。
你(当前词)有一个 Q:
“我需要一个懂 AI 的人。”
公司里每个人都有一个 K:
- 小明:K = “我懂 AI”
- 小红:K = “我懂设计”
- 小刚:K = “我懂 AI”
你用你的 Q 去对比所有人的 K:
- 小明匹配度高
- 小刚匹配度高
- 小红匹配度低
然后你把他们的 V 拿过来:
- 小明的 V = “AI 工程师,会深度学习”
- 小刚的 V = “AI 研究员,会大模型”
最后你得到一个综合后的自己:
“我现在知道我应该找小明和小刚合作。”
这就是自注意机制。
为什么一定要分成 Q、K、V?
因为要把 “搜索条件” 和 “被搜索的标签” 和 “实际内容” 分开,这样:
- Q 可以专注于 “我要找什么”
- K 可以专注于 “我能被怎么找到”
- V 可以专注于 “我能提供什么”
这种分离让模型表达能力更强,也更灵活。
如果只用一个向量,就像让一个人同时当:
- 求职者
- 面试官
- 简历内容
会非常混乱。
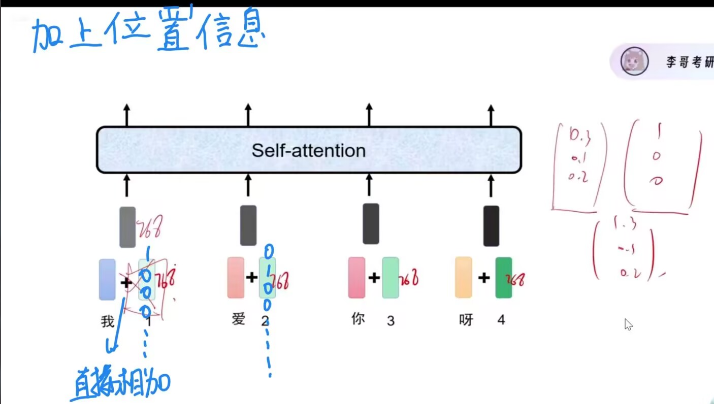
最后再加上位置信息
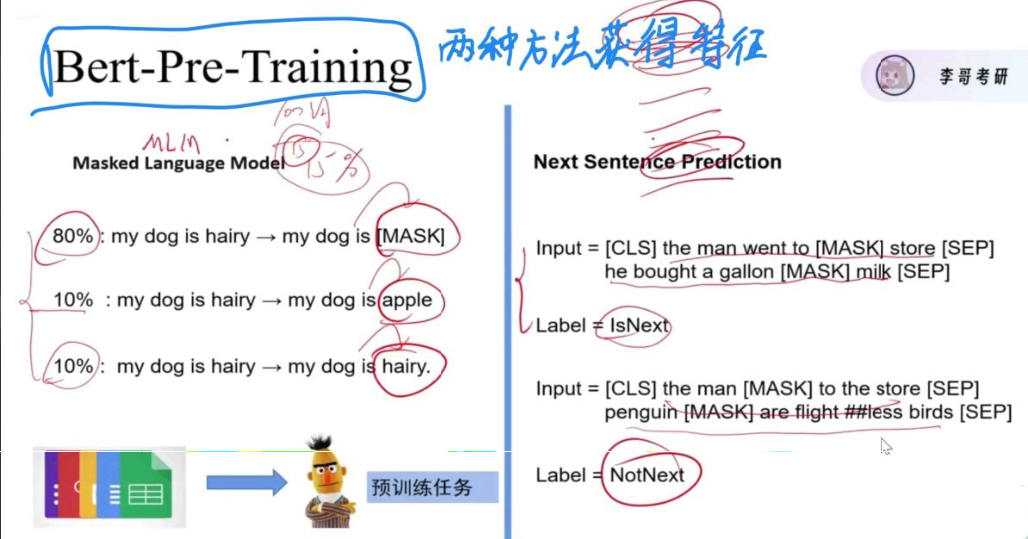
有两种方法获得特征
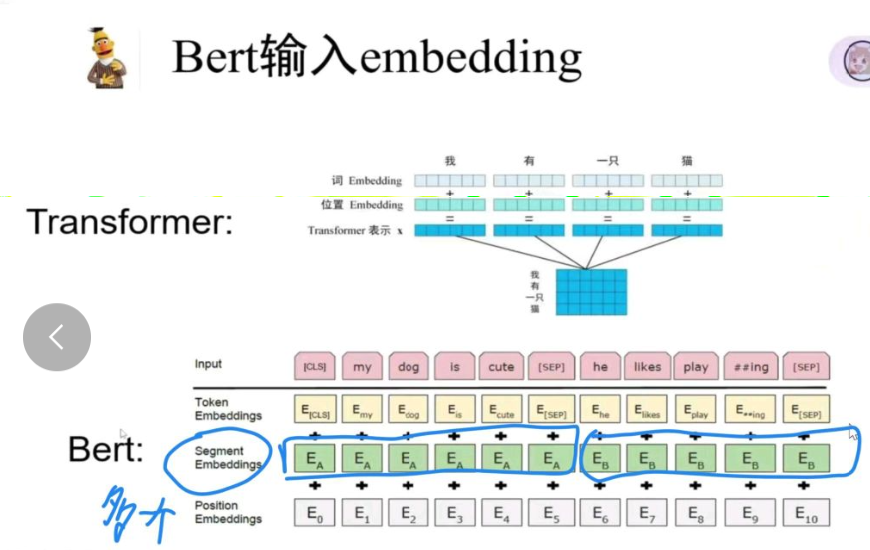
BERT的输入比transformer多一层
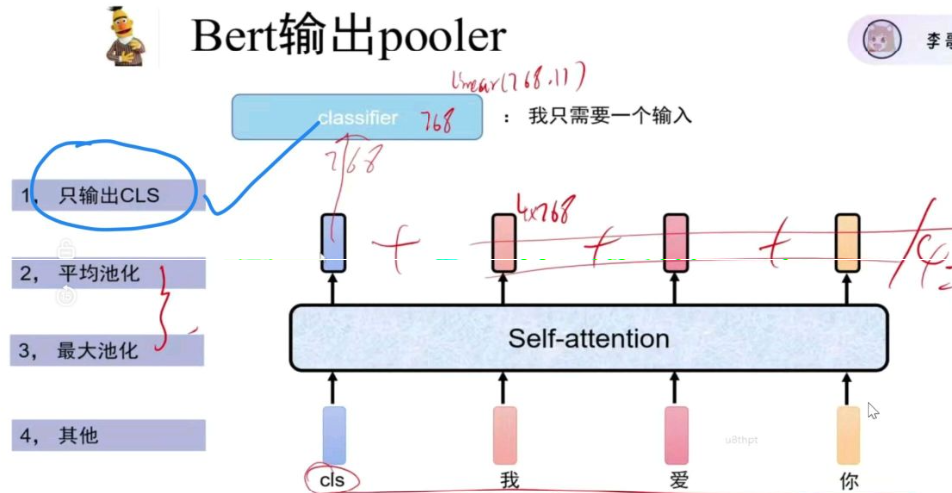
Bert的输出pooler有很多种方式,但一般都是第一种
[CLS] 是 BERT 预训练阶段专为「句子全局语义」设计的 token,有先天的任务对齐优势;
[CLS] 效果稳定、提取成本低,适配绝大多数下游任务(分类 / 识别 / 匹配等);
总结

一、多层感知机(MLP):最基础的 “深度学习积木”
1. 核心定义
多层感知机(Multi-Layer Perceptron,MLP)也叫全连接神经网络,是由输入层、至少一层隐藏层、输出层组成的简单深度学习模型,每层的神经元都和下一层所有神经元 “全连接”,且隐藏层会用激活函数(如 ReLU)引入非线性,让模型能学习复杂规律。
2. 通俗比喻
可以把 MLP 理解成 “流水线式的信息处理器”:
- 输入层:收集原始信息(比如文本的词向量、图片的像素值);
- 隐藏层:对信息做层层加工(比如从 “交通标志的颜色 + 形状” 中提取 “红灯 / 绿灯” 的特征);
- 输出层:给出最终结果(比如判断这是 “禁止通行” 标志,或文本的情感是 “正面”)。
3. 关键特点 & 与 BERT 的关联
- 结构简单但通用性强:是深度学习的基础,几乎所有复杂模型(包括 Transformer/BERT)都包含 MLP 组件;
- BERT 中的 MLP:BERT 的 Transformer 编码器每一层里,都有一个 “前馈神经网络(FFN)”,这个 FFN 本质就是两层 MLP(第一层线性变换 + ReLU 激活,第二层线性变换),作用是对自注意力层输出的特征做进一步的非线性变换;
- 下游任务中的 MLP:BERT 做文本分类时,[CLS] token 的输出通常会接一个简单的 MLP(比如 “线性层 + Softmax”),完成从语义特征到分类结果的转换。
二、MLM(Masked Language Model):BERT 的 “完形填空” 训练法
1. 核心定义
MLM(掩码语言模型)是 BERT 预训练的核心任务之一,核心逻辑是:随机 “遮挡” 文本中的部分词(token),让模型根据上下文预测被遮挡的词是什么,以此让模型学习文本的上下文语义关联。
2. 通俗比喻
就像我们做英语 / 语文的 “完形填空”:
原句:今天的天气真不错
掩码后:今天的 [MASK] 气真不错
模型需要预测 [MASK] 的位置应该填 “天”—— 这就是 MLM 的核心目标。
3. BERT 中 MLM 的具体做法(关键细节)
为了让模型真正学习语义而非 “作弊”,BERT 的 MLM 做了特殊设计:
随机选择文本中 15% 的 token 进行处理:
- 80% 的概率替换成特殊符号
[MASK](比如 “天气”→“[MASK] 气”); - 10% 的概率替换成随机的其他 token(比如 “天气”→“汽车”);
- 10% 的概率保留原 token(比如 “天气” 还是 “天气”);
- 80% 的概率替换成特殊符号
模型基于上下文预测这些被处理的 token,通过预测误差更新参数,最终学会 “结合上下文理解语义”。
4. 核心作用
MLM 是 BERT 具备 “双向上下文理解能力” 的关键 —— 因为要预测被掩码的词,模型必须同时看左边和右边的文本(比如预测 “[MASK] 气”,既要看 “今天的”,也要看 “真不错”),这也是 BERT 区别于 GPT(只能单向看前文)的核心特征。
总结
- 多层感知机(MLP) 是基础的全连接神经网络结构,是 BERT 内部 Transformer 层、下游分类任务的核心组件,负责特征的非线性变换和分类;
- MLM(掩码语言模型) 是 BERT 的预训练任务,通过 “完形填空” 让模型学习双向上下文语义,是 BERT 具备强语言理解能力的核心原因;
- 两者的核心区别:MLP 是 “模型结构”,MLM 是 “训练任务”,前者是 “工具”,后者是 “使用工具的方法”。
 微信
微信 支付宝
支付宝