
第八节Bert实战
对于输入需要分词
输入的序列前面需要加上cls,,后面需要加上seq。
在这个基础上如果凑不够input的值,,则会填充两个padding。
输入被分成三部分

Bert的参数
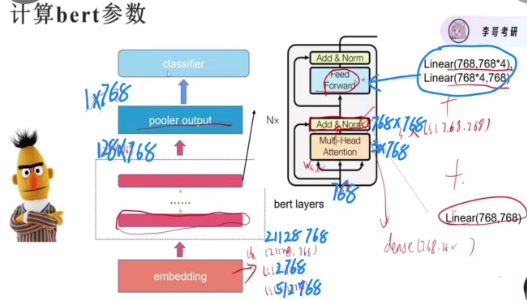
768在Bert中有什么特殊含义?为什么特征都是768的?
相当于一个约定俗成的值,因为这是Bert-base版本(折中了参数量和效率)中,每个 token(词 / 字)经过 Embedding 层和 Transformer 层后,输出的向量维度是 768 维。那为什么是768?BERT-base 的 Transformer 层有12个注意力头(num_attention_heads=12),而注意力机制要求hidden_size必须能被注意力头数整除(方便将 768 维向量均分给到 12 个头):768÷12=64。每个注意力头负责处理 64 维的子向量,这是 Transformer 注意力机制的核心要求(均分维度保证计算效率)。
embedding层的三个输入分别是什么
21128是指中文词表有21128种
2是指segment——embedding只有01两种,所以是2
512是指模型的最大长度为512,在这个范围之内选择一个适合你数据集的长度(如果句子比较短可以选32,比较长可以选128等)
Bertlayers里面有什么
bertlayers里面有很多selfattension层,进入的时候是768维,被分成三部分QKV进入multi-head,add&norm中还有一个dense层(768*768)用来特征的进一步提取。
另外,这些乘式前面都会乘上batchsize
forward层中,第一步是分词器,那这三个是干啥的
1 | input = self.tokenizer(text, return_tensors="pt", truncation=True, padding="max_length", max_length=128) |
(1) input_ids
含义:文本经过分词后,每个 token(词 / 子词)对应的数字编码(词典 ID)。模型的核心输入,本质是把 “文字” 映射成 “数字”,让模型能计算。
通俗例子:
比如文本是 “我爱编程”,tokenizer 分词后可能得到
1
['我', '爱', '编', '程']
,对应的词典 ID 可能是
1
[2769, 4263, 7746, 6241]
,这就是
1
input_ids
的值。
代码中作用:
input_ids.to(self.device)是把这个张量放到指定设备(CPU/GPU)上,供模型计算。
(2) token_type_ids
含义:
用于区分文本中的不同段落 / 句子(主要用于成对文本任务,比如问答、句子匹配)。
- 通常:第一句的 token 标记为
0,第二句的 token 标记为1;如果只有单句,所有 token 的token_type_ids都是0。如果三句,00001111000000
- 通常:第一句的 token 标记为
通俗例子:
文本是 “问题:什么是编程?回答:编程是写代码”,分词后:
1
['问','题',':','什','么','是','编','程','?','答','案',':','编','程','是','写','代','码']
对应的
1
token_type_ids
可能是:
1
[0,0,0,0,0,0,0,0,0,1,1,1,1,1,1,1,1]
代码中作用:模型通过这个标识区分不同句子,处理跨句依赖(比如 BERT 的 Next Sentence Prediction 任务);如果是单句任务(如文本分类),这个值其实不影响结果,但 tokenizer 仍会返回,所以需要传入模型。
(3) attention_mask
含义
:用于标记哪些 token 是真实有效的,哪些是填充(padding) 的,避免模型关注填充的无效 token。
1表示有效 token(真实文本),0表示填充的 token。
通俗例子:
你代码中设置了
1
max_length=128
,如果文本分词后只有 10 个 token,那么剩下的 118 个位置会被填充,此时:
1
attention_mask = [1,1,...,1,0,0,...,0]
(前 10 个是 1,后 118 个是 0)。
代码中作用:模型的注意力机制(Attention)会根据这个掩码,只计算
1对应的 token,忽略0对应的填充部分,保证计算结果的准确性。
调试阶段
在model文件中的input = self.tokenizer(text, return_tensors=”pt”, truncation=True, padding=”max_length”, max_length=128)打上断点????????
转到model文件的BertModel,转到用法,发现初始化里面是三层:embedding、encoder、Pooler层
点进去embedding层,在if input_ids is not None:打上断点,F9执行到此处。
会发现embedding里面是word_embeddings、position_embeddings、token_type_embeddings
 微信
微信 支付宝
支付宝